Topic Modeling - 1. 개요
토픽 모델링
강필성 교수님 유투브를 보면서 노트를 적었습니다.
유투브 보시기를 바랍니다.
유투브 링크: www.youtube.com/watch?v=J1ri0EQnUOg&list=PLetSlH8YjIfVzHuSXtG4jAC2zbEAErXWm&index=13
(단어 차원)
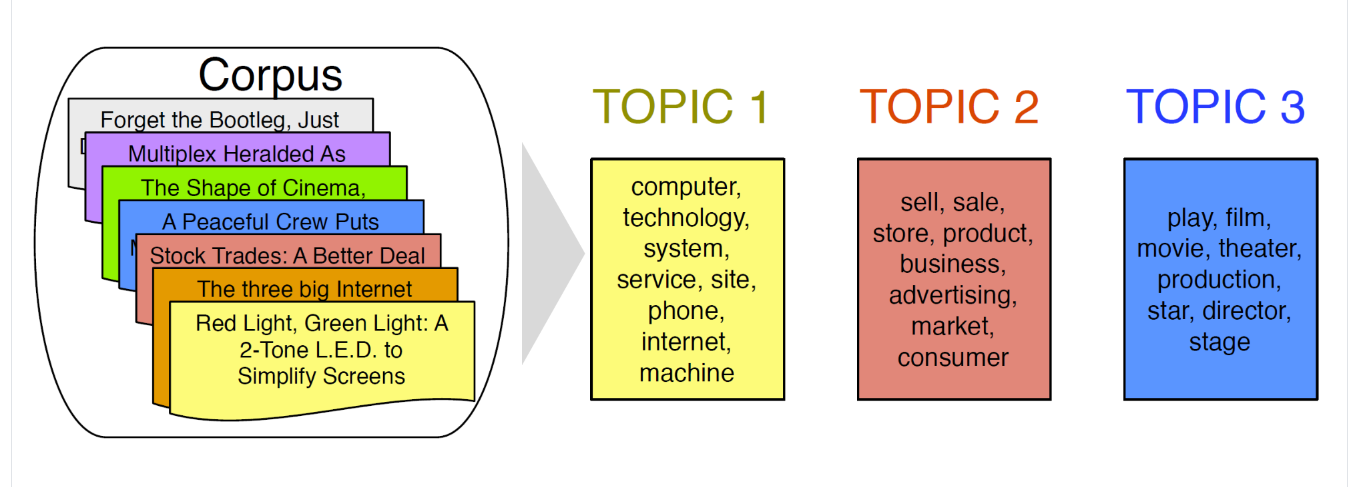
각 Corpus들을 가져와서 K 개의 토픽을 만들도록 설정하면 K 개의 토픽이 생성이 되고,
각 토픽(주제)에 해당하는 높은 빈도의 어휘들을 할당한다.
(문서 차원)
각 개별적인 문서가 어떤 토픽을 가장 많이 내포하고 있는지를 파악할 수 있다.

노란색은 1번 토픽 단어들을 많이 내포하고 있고, 3번은 3번 토픽을 많이 내포하고 있지만,
회색같은 경우는 모든 토픽의 단어들을 비슷한 비중으로 가지고 있다.
각 문서들의 토픽 분포 비교

점들은 각 문서들을 뜻하고, 오른쪽의 그래프는 토픽들의 분포를 표시하고 있다.
오른쪽 두 점 같은 경우는 토픽들의 분포의 차이를 계산해 0.21이라는 수치를 산출, 유사하다는 결론이 나왔다.
토픽 모델링 차트

딥러닝을 총 7개의 토픽으로 나눠도,
토픽들끼리 더 유사하다면, 거리가 가깝고 아니면 거리가 먼 방식으로 계산이 되고 있다.
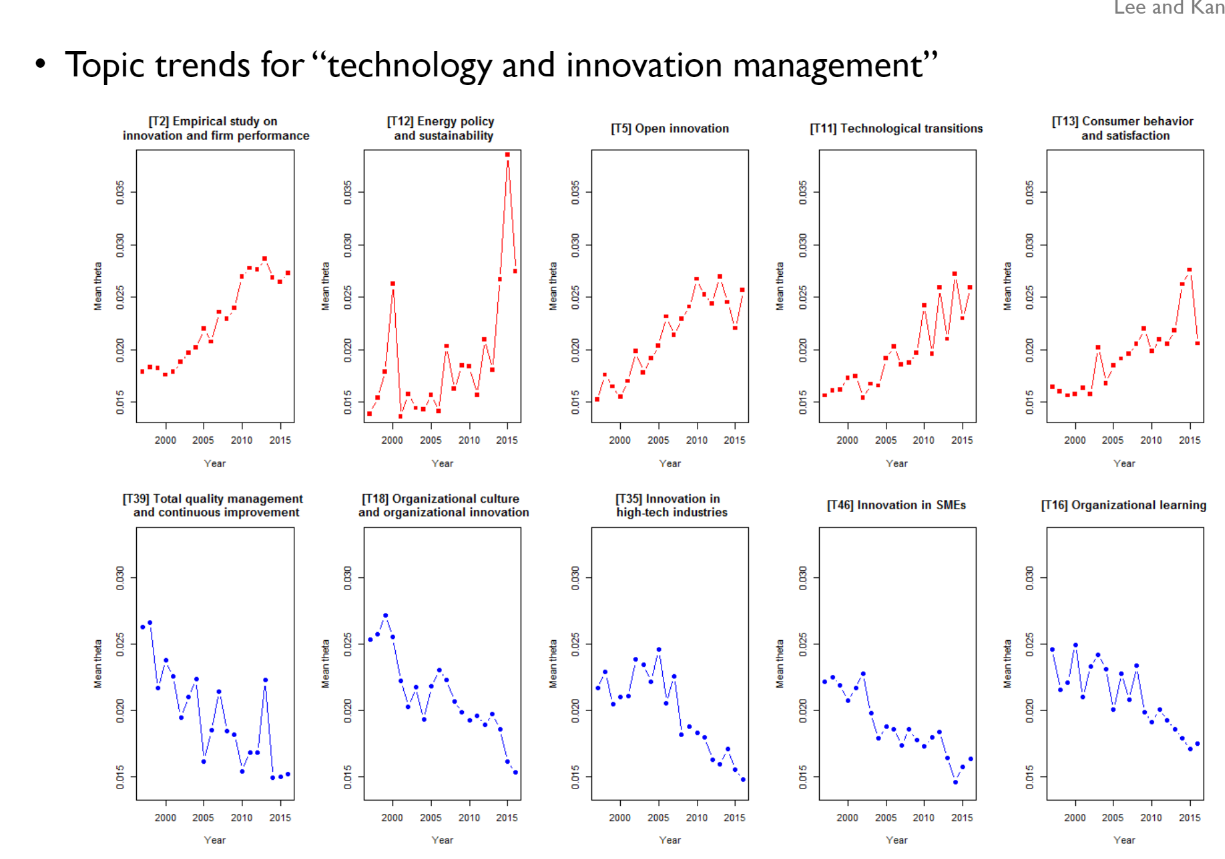
논문 내에서 각 토픽들을 시계열(연도별)적인 그래프로 표현한 그래프이다.
위 빨간 그래프 같은 경우는, 시간이 지날수록 언급이 더 많이 되는 HOT TOPIC이고,
아래 파란 그래프 같은 경우는, 시간이 지날수록 언급이 점점 줄어드는 COLD TOPIC이다.
유사한 토픽을 가진 잡지 찾기

BEATZ를 250개 토픽을 찾은 후, 유사한 토픽 분포를 가진 잡지들을 찾는 것이다.
동일한 잡지, 다른 호수의 BEATZ가 유사한 잡지로 뽑혔고 그 다음에는 HM이라는 잡지가 비슷한 잡지 형태로 뽑혔다.